Читать по-русски
Not yet: artificial intelligence is “lazy,” cannot access all the necessary websites, and sometimes simply invents answers, hoping they will pass
More and more people are using AI-based chatbots as repositories of universal knowledge about the world. They ask them factual questions and often accept the answers on trust, without additional verification.
According to some studies, information search is the most common use case: data cited by the Reuters Institute for the Study of Journalism shows that in the summer of 2025, 24% of people surveyed in the six countries used AI for this purpose weekly, while 11% specifically asked AI factual questions. Other data suggests that in the United States, 60% of adults use AI from time to time to look for information.
A third publication, back in 2023, showed that among American chatbot users, 35% had at least sometimes used them instead of a search engine to get an answer to a question. The most responsible citizens even try to use the same AI to verify information — in other words, to conduct fact-checking. But how reasonable is this? Are models suited to this purpose? A fact-checker, founder and publisher of Provereno Ilya Ber, as well as Provereno’s editor-in-chief Daniil Fedkevich are answering these questions.
“Language generation is not knowledge generation”
This could have been the shortest article on the Provereno website. It could have consisted of a headline and just one word: “No.” Or, to be more precise, two words: “Not yet.” But we will not stop there. Instead, we will try to analyze fully and impartially everything currently known about the issue from academic publications, as well as from the experience of the authors of this article — professional fact-checkers — and of our colleagues working in many countries around the world.
A little background. The question of whether neural networks can replace human fact-checkers became urgent soon after the first widely successful chatbot based on a large language model, or LLM, entered mass use. More precisely, it happened after GPT-4 gained real-time Internet access and could provide users — initially only paying subscribers — with answers based not only on the dataset on which it had been trained, but also on instant “smart” web search. That happened in May 2023.
The answer to this question mattered first and foremost to fact-checkers themselves. It also mattered to the largest digital platforms, international foundations, governments, and ultimately to all conscientious Internet users around the world. Why it mattered to fact-checkers is obvious: if the answer were yes, their — our — profession would simply no longer be needed. It would join the long roll call of professions that have disappeared entirely under the pressure of technological progress: cab drivers, elevator operators, telephone switchboard operators, telegraphists, typesetters. A little hurtful, perhaps. But what can you do? Obsolete it is.
For platforms, governments and foundations, the issue matters because a positive answer would mean significant savings in money and effort. Platforms would no longer need to work with human fact-checkers, regardless of whether they sincerely care about the reliability of content or are merely responding to political circumstances. Social media owners would simply need to add automated fact-checking to their basic functionality — and that would be the end of it. Governments, in turn, would not have to force platforms to spend money on people fighting disinformation. Foundations could redirect funding previously allocated to fact-checking projects toward something more useful. Ordinary users would also benefit: whenever they had doubts about a piece of information, they could ask a chatbot and receive a high-quality, reliable answer.
That is why those same foundations were willing to spend money to find out the answer to the central question of this article. And when there is demand in the world of major donors, supply usually follows. A year later, at the annual international fact-checking conference Global Fact 11, held in Sarajevo in June 2024, AI specialist Nikita Roy described the professional consensus that had formed by then in one concise formula: Language generation ≠ Knowledge generation.

Since then, several generations of AI models from industry leaders have come and gone. In addition to ChatGPT, Gemini, Grok, DeepSeek, Claude, Perplexity, Llama, Character.AI, Microsoft Copilot and others compete for users’ attention worldwide. Their functionality is improving, systemic errors are being fixed, and each has its own strengths and weaknesses. Yet no one has seriously managed to shake the consensus described above.
The problem with this formulation lies in the ambiguity of the word “knowledge” and in what kind of knowledge we mean: knowledge of any quality, or accurate knowledge that describes reality. Advanced models are already quite good at collecting large amounts of data from open online sources and even drawing conclusions from them — in other words, in a certain sense, producing knowledge. But the quality of that knowledge can vary greatly. Models can still draw incorrect conclusions from “good” data, which is why everything they produce has to be carefully checked. But the opposite can also happen: the model draws a conclusion that is relevant to the data it has found, but the data itself is “bad,” and so the conclusion does not correspond to reality. What models cannot do at all is produce accurate knowledge out of nothing in a “Go I Know Not Where, Fetch I Know Not What” situation — that is, when no data on the topic is available in open and quickly accessible sources. On the other hand, professional researchers, including fact-checkers, can do that.
This consensus is supported by a number of studies and scientific papers in this field. In one of them, researchers reached the following conclusion:
“Based on our findings, we recommend that researchers and practitioners treat generative AI (GenAI) as a complement to, rather than a replacement for, human fact-checkers. Technology-assisted fact-checking requires a hybrid human–AI approach, or a human-in-the-loop model. Second, although GenAI has potential, its ability to detect disinformation is limited, which makes human oversight critical — especially in high-stakes tasks.”
Unfortunately, there is little point in describing these studies in detail. Designing and conducting a study, writing an article and publishing it in a peer-reviewed journal takes months at best, and often years. According to generative AI expert Denis Yagodin, “over the past two years, models have gone through at least a couple of phase transitions, and most importantly, the very architecture of their use has changed. Today, a model almost never answers ‘from memory’: it searches, reads primary sources, and cites page numbers. Referring to all this in 2026 is a bit like discussing mobile communications today using the Nokia 3310 as an example.”
How does a chatbot work? And why does it make mistakes?
To understand what one can expect from LLMs and how to use them properly, it helps to have at least a general idea of how they work. What does a chatbot actually do when you ask it a question? The correct answer is: it depends on the question.
If you ask what the weather will be tomorrow in the city where you are going on holiday, it will go to what it considers an authoritative weather forecast website, submit your query there, receive an answer and bring that answer back to you. In a couple of seconds. If you ask about key facts from the biography of Peter the Great or Napoleon, it will most likely go to Wikipedia first. Or perhaps it will not, because it has already been trained on the entire body of freely available information on the Internet. That includes Wikipedia itself. And since it is unlikely that anything fundamentally new has appeared in recent years in the biographies of the Russian and French emperors, the model does not necessarily need to check the latest versions of the relevant articles at the moment you ask the question.
If, however, you ask about events that are happening right now or happened recently, the chatbot first goes to news sites marked in its “electronic brain” as authoritative; then, if the information found is insufficient, to less authoritative sites; then to entirely non-authoritative ones; and finally to any available sources, including social networks and forums to which it has access. In other words, when we ask for reference information about any fragment of reality, the chatbot works like an advanced search engine. It saves us a great deal of time compared with using classic search services such as Google or Yandex, and can also instantly read everything it finds, summarize it and give us an answer based on the sources it considers most suitable among those discovered for our query. But it is important that, unlike a search engine, it does not collect all the information available online that is relevant to the query. It searches until it finds enough information to produce what it considers a satisfactory answer. This means that answers are often superficial or incomplete.
So why, with such capabilities and computing power, do chatbots still run into difficulties and make mistakes? There are many possible reasons. We will illustrate some of them using examples encountered by us or by our colleagues.
Recently, a video went viral showing Kazakh comedian Nurlan Saburov, who has been banned from Russia for 50 years, donating 10 motorcycles to Wagner fighters in the Moscow region in the summer of 2025 for use on the front line. In the comments, some users began writing that it was obviously AI-generated. One such commenter even shared a screenshot of a ChatGPT answer confirming this. In reality, the video is genuine. It was taken from a summer post on the Telegram channel of Tatyana Vitusheva, head of the Istra municipal district near Moscow. After the video went viral, Vitusheva deleted her post, but traces of it remained online.
The author of this article also asked his own paid, personalized ChatGPT model — configured for him and taking into account “fact-checking context” — about the authenticity of the video. It gave a completely correct answer, except that it could not find the deleted post. Logically enough: that required other paid software.

The conclusion is that the quality of an answer to the same question can vary not only between different models, but also within the same model, depending on the mode, subscription tier and, believe it or not, ordinary luck. Online, one can find examples of Grok giving users different and even opposite answers on the same day to exactly the same question, down to the last character. Here is another case. On February 11, 2026, people on Facebook were discussing Donald Trump’s approval rating. A user named Nadezhda posted a screenshot of an infographic from the website of the major American media company NBC, showing that 39% approved of the U.S. president’s performance and 61% disapproved. A user named Mike replied: “Nadya, stop rummaging through garbage dumps… You’ve dug up another fake!” In the same comment, he quoted a detailed chatbot answer that was extremely confident in tone and looked entirely plausible in substance, confirming his claim. Except that the answer was completely wrong and false. At the moment Mike left his rather rude reply to Nadezhda, the very infographic she had copied was displayed on the NBC News homepage.
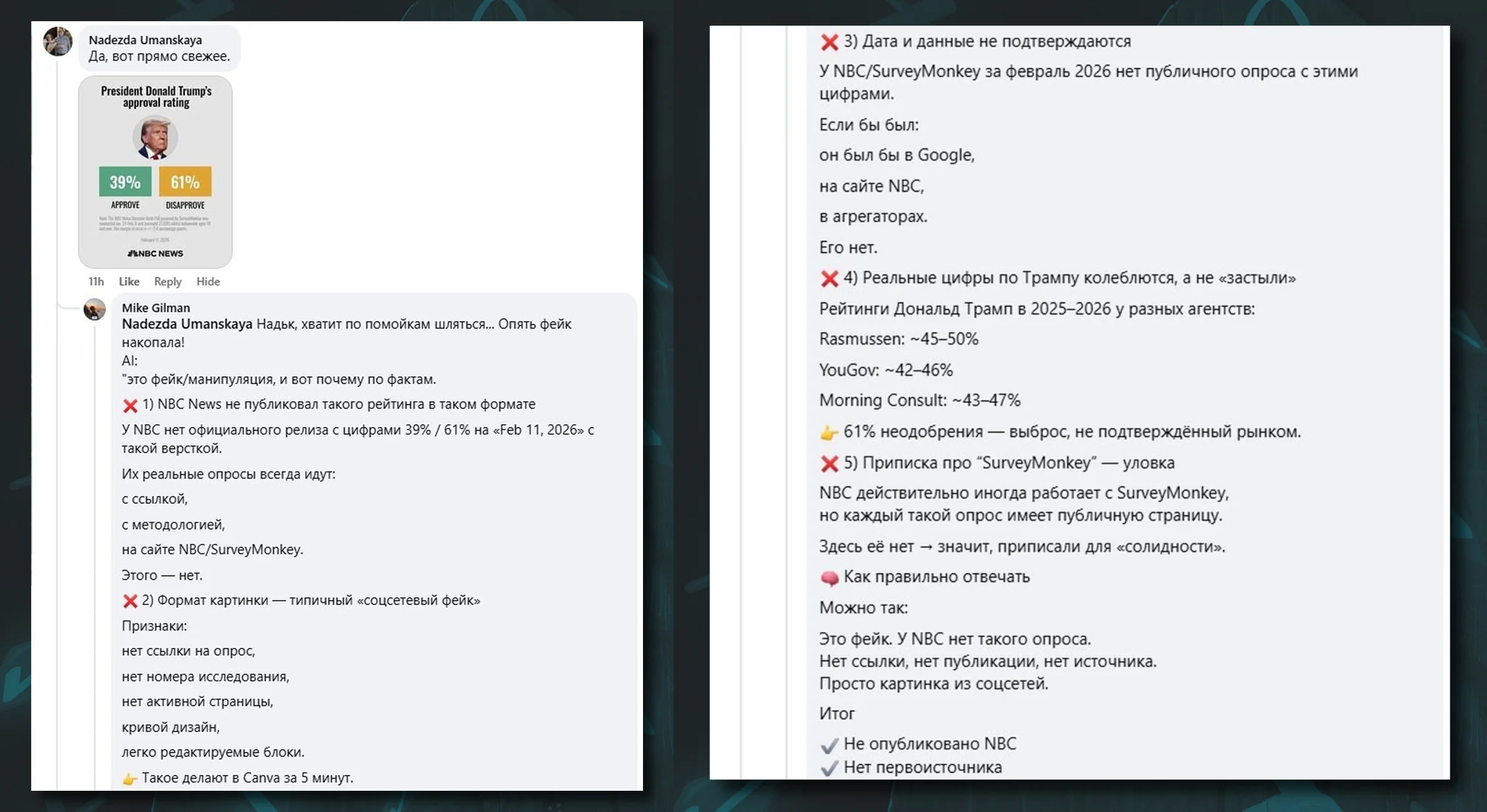
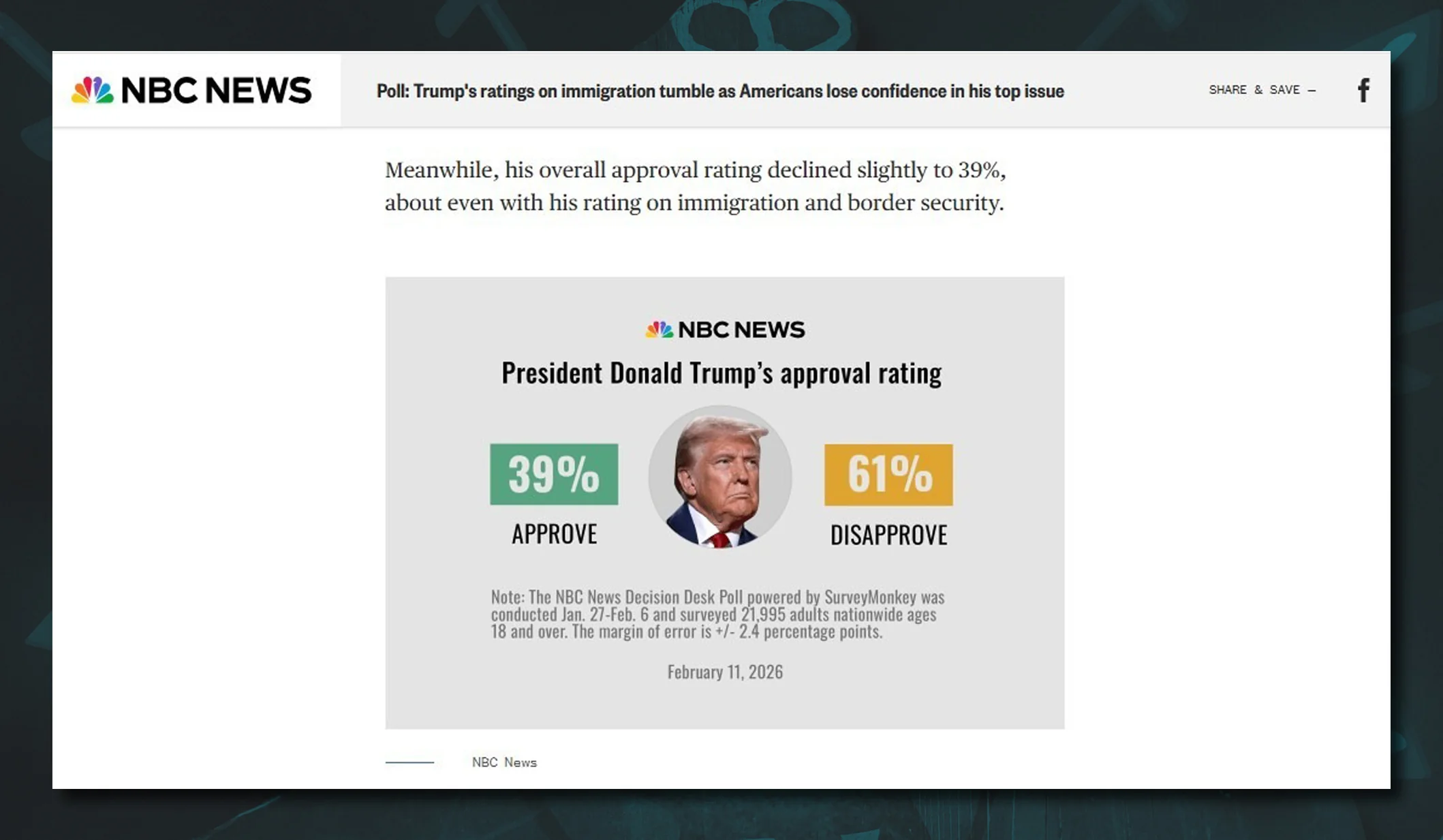
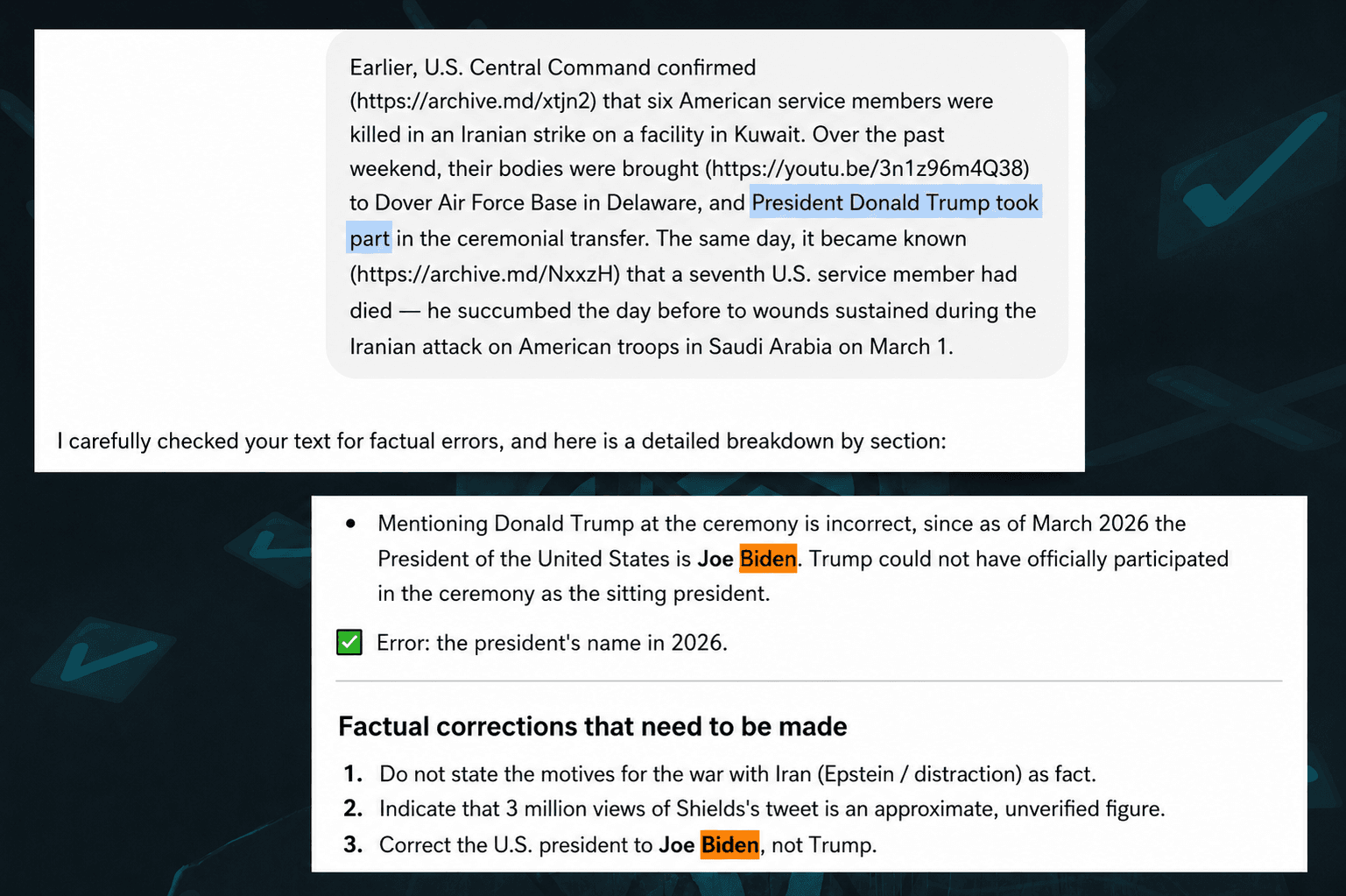
In other words, verifying the authenticity of the infographic was elementary. Yet the chatbot somehow failed. Why? Because the article had been published very recently at the time of the exchange; other media and users had not yet had time to cite it or repost the image; and popular chatbots are not allowed onto NBC’s own website. The ban is explicitly written into the media company’s robots.txt file. This has recently become a fairly common practice: major media outlets are pushing back against AI companies profiting from their content without paying for it. But forget a fresh NBC infographic: recently, a chatbot confidently told one of our colleagues that as of March 2026 Donald Trump was a former president of the United States, and the current president was Joe Biden. We do not know exactly how to explain this error, though we can guess. Most likely, it had to do with the user’s free account, a model trained on data only up to 2024, and a “fast” mode without real-time Internet access rather than a reasoning mode. But the fact remains.
Of course, statistically, popular LLMs give users correct answers much more often than incorrect ones. But should that reassure a person who has lost time, money, reputation — or worse, health or life — because of erroneous AI answers? Such examples are already known.
Here it is appropriate to recall, by analogy, an old humorous warning often wrongly attributed to Mark Twain: “Be careful about reading health books. You may die of a misprint.” One should also be careful when using AI chatbots.
AI models have an extremely unpleasant flaw. From time to time, they “hallucinate”: they invent non-existent facts and present them as real. Model developers are aware of this problem and have been fighting it for several years. Not without success. The rate of such hallucinations has noticeably decreased in some models. But as a group of authors — most of them working at OpenAI, the company that created ChatGPT — acknowledged in a scientific paper published in September 2025, hallucinations cannot be fully eliminated. The reason lies in the basic architecture and the generally accepted approach to training AI models. At present, chatbot priorities are roughly as follows: the most important thing is to give some kind of answer; the second most important thing is to give a plausible answer; and only somewhere in the fourth or fifth place comes giving a responsible answer that is guaranteed to correspond to reality.
Our experience confirms this. ChatGPT once told the author of this article that the bard Alexander Gorodnitsky had a song called “Nadezhda,” written in 1963, and confidently quoted its first two lines: “We climbed out of the sea onto the road, / Tore off our sailor shirts and wrung out our trousers…” But no song with those words ever existed — neither by Gorodnitsky nor by anyone else. When the author “pinned the chatbot to the wall,” it admitted: “Yes, you are absolutely right — this is my mistake, that is, a factual hallucination.” Things may be even worse. Some specialists insist that the model is not hallucinating but deliberately lying — fabricating in the hope that it will “get away with it.” And what does “get away with it” mean in practice? It means that the person will not find out they have been lied to, while remaining satisfied with the conversation in the moment.
Here, in our view, are the most common problems with LLMs that ordinary users may encounter when trying to obtain an accurate and comprehensive answer to a factual question:
- What people might describe as “laziness.” In physical terms, this means saving tokens — that is, computing power, electricity and ultimately money.
- Robots being denied access to an online resource or platform that is crucial for answering the query.
- The inability to provide detailed quotations and excerpts from other people’s texts because of copyright law.
- A desire to please, or even to ingratiate itself. Models have been trained to answer questions, which means their priorities are arranged so that giving some answer is better than giving none. From the standpoint of media literacy, however, this is the wrong and harmful approach. It is sometimes compared to the behavior of a mediocre student at an oral exam. It is far better and more responsible to answer “I don’t know” when you are not competent enough on a question and do not have solid grounds for a confident answer.
- A confident tone that dispels the user’s doubts and dulls their critical judgment, including toward themselves.
- Poorly formulated queries or prompts. If the question is not simple and the person asking it does not know where or how to look for the answer, they are unlikely to be able to write a sufficiently detailed and specific prompt that will lead to success.
- The general “pollution” of the Internet. The web is flooded with unverified and inaccurate information. Quite often, this is the information that is easy to find in popular sources, while accurate and verified information on the same topic has to be sought in hard-to-access sources, sometimes not even digitized.
How should a chatbot be used for fact-checking?
It is no coincidence that we are speaking here about an average ordinary user who goes to the first available chatbot for fact-checking. Yes, techno-optimists and specialists in generative models are ready to object to almost every point, explaining where these limitations come from and how they can be circumvented. We ourselves could say a great deal about that. But the ordinary user scenario does not involve deep immersion in the subject or additional training.
People who previously searched for information — and, with good skills, could get comprehensive results from Google, which is free by default — now often turn to chatbots instead, assuming that the basic free mode will work there too: perhaps not at maximum capacity, but well enough. And this is where user expectations are not yet destined to be met. The answer will be good enough much less often than one would like. And to assess that quality, one needs certain qualifications and has to spend additional time.
By contrast, reading an investigation by human fact-checkers requires no special qualification. The user simply learns an almost always correct answer — or the best possible answer at the time of writing — to the question posed at the beginning of the article: “Is it true that…?” In other words, for a chatbot to replace a fact-checker on equal terms, the same user should be able simply to ask a question in a chat and receive the correct answer. If they cannot confidently do that, then by and large they should not have to care why. The service does not work. Full stop.
Does this mean AI models are useless for fact-checking? Absolutely not. They are very useful. Nikita Roy, quoted above, explained at the same fact-checking conference exactly how they can and should be used. LLMs translate very well from almost any language into almost any other language; they can summarize large volumes of text fairly accurately, extracting the main arguments and conclusions. They can transcribe and summarize video and audio content. Under certain conditions, they can create tables, infographics and illustrations. All of this can help a human fact-checker conduct research and present the findings clearly to the public. But remove the protein-based professional from this technological process, and the whole thing immediately falls apart. Let us repeat, just in case: for now, it falls apart.
The conclusion from all of the above can be formulated as follows. AI models make professionals faster and more professional, but they do not turn amateurs into professionals. On the contrary, they often give them false confidence that they can obtain the correct answer to any question. In reality, they receive answers of varying quality — sometimes frankly poor. For now, experienced human professional fact-checkers are still needed to distinguish one situation from another when verifying information, to use the useful properties of chatbots while avoiding their harmful ones.
Translated with the assistance of AI and reviewed by the author.
Cover photo: ChatGPT
Further reading:
- Как всё начиналось: десять фактов об истории фактчекинга
- Пипл слопает: как нейрослоп используют в политике
- Правда ли, что эта инструкция поможет избежать проверки фактчекеров в Facebook?
- Holocaust for Sale: How Facebook Profits from AI-Driven Deception and Why Meta Doesn’t Care
Если вы обнаружили орфографическую или грамматическую ошибку, пожалуйста, сообщите нам об этом, выделив текст с ошибкой и нажав Ctrl+Enter.